高并發場景下,如何實現數據庫主從同步?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
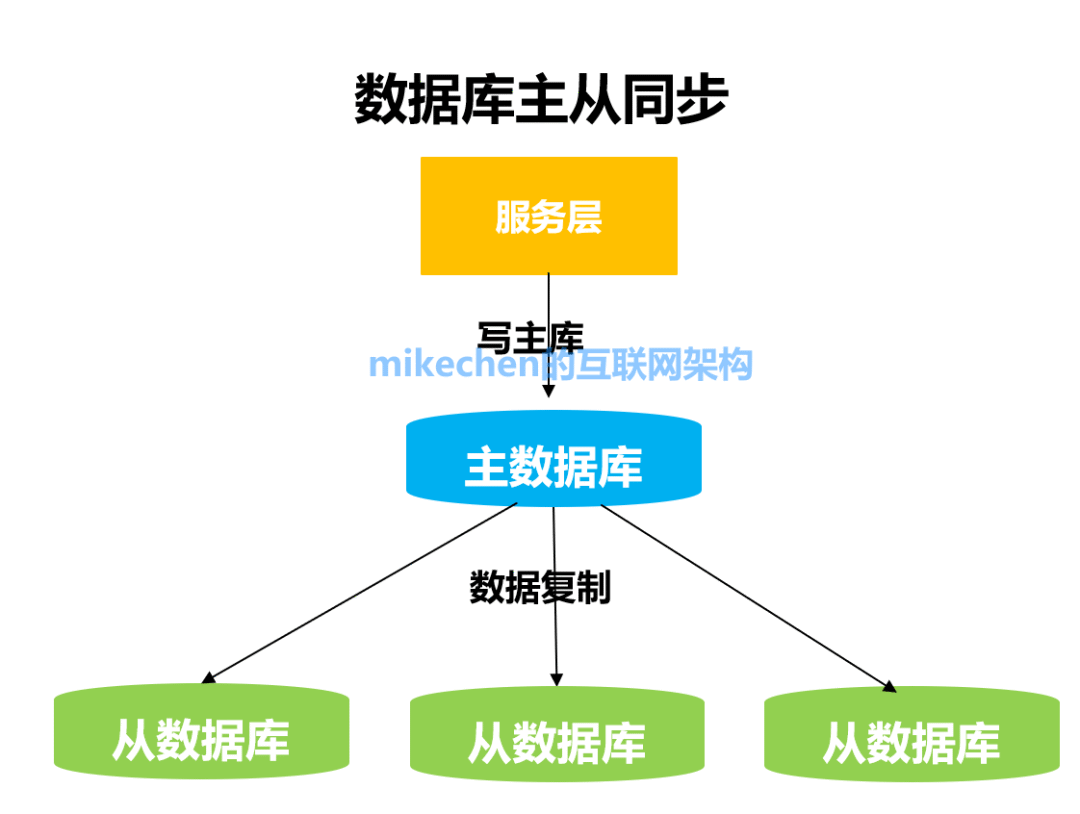
數據主從同步的由來互聯網的很多業務,特別是在高并發的場景下,基本都是讀遠遠大于寫,如果數據庫讀和寫的壓力都同在一臺主機上,這顯然不太合理。 于是,把一臺數據庫主機分為單獨的一臺寫主庫(主要負責寫操作),而把讀的數據庫壓力分配給讀的從庫,而且讀從庫可以變為多臺,這就是讀寫分離的典型場景如下:
為了進一步的降低數據庫端的壓力(高并發的瓶頸),這個時候也會在業務層部署分布式緩存集群(redis、memcached)等,把讀的壓力轉移給應用服務器端,其實與數據主從的設計是遵循同一個原則,降低后端數據庫的壓力。 問題: 讀寫分離提高了資源的利用效率的同時也引出了一個問題,就是由于延時(網絡傳輸,操作)而引起的數據庫主從不一致的問題,以下會詳細談相關的數據一致性解決方案。 數據同步一致性解決方案1.半同步復制 辦法就是等主從同步完成之后,等主庫上的寫請求再返回,這就是常說的“半同步復制"。 實現方案 mysql的半同步復制方案,下面我以mysql為例介紹。
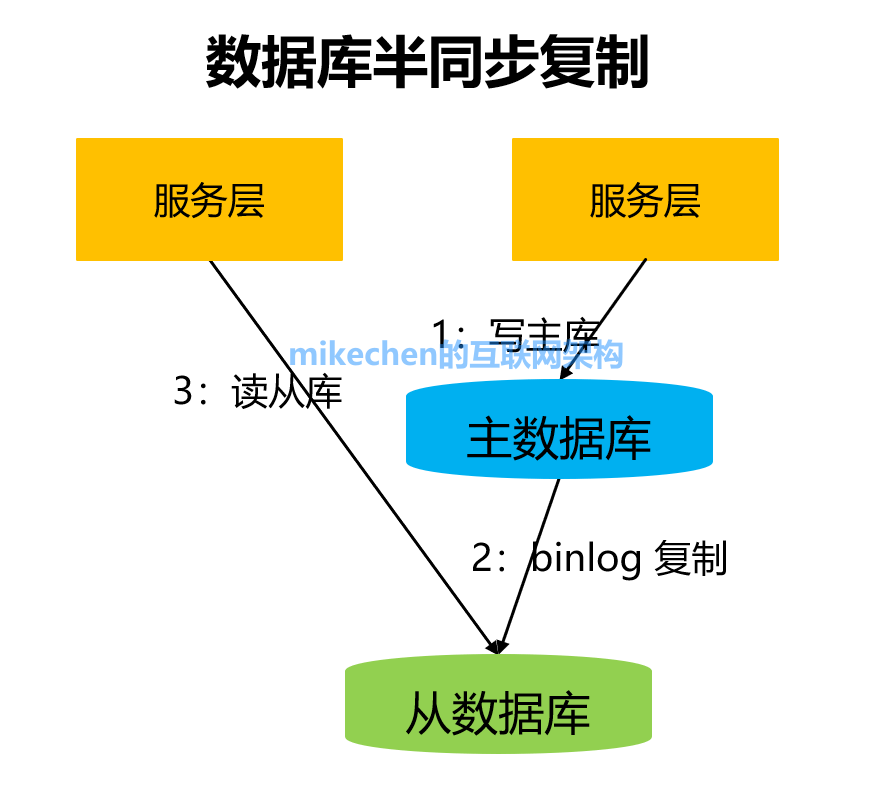
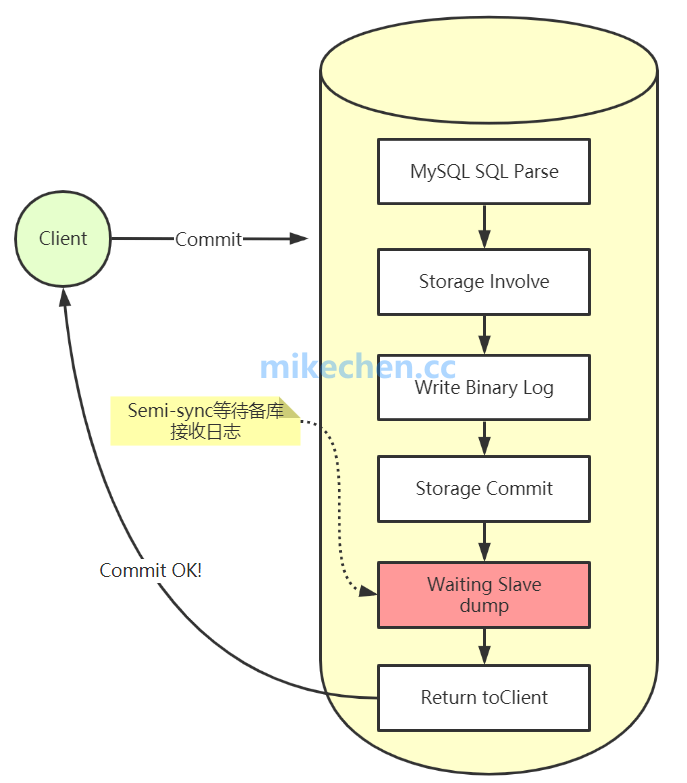
MySQL半同步復制 MySQL的Replication默認是一個異步復制的過程,從MySQL5.5開始,MySQL以插件的形式支持半同步復制,我先談下異步復制,這樣可以更好的理解半同步復制。 1)異步復制 MySQL默認的復制是異步的,主庫在執行完客戶端提交的事務后會立即將結果返給給客戶端,并不關心從庫是否已經接收并處理,這樣就會有一個問題,主如果crash掉了,此時主上已經提交的事務可能并沒有傳到從庫上。 2)半同步復制 介于異步復制和全同步復制之間,主庫在執行完客戶端提交的事務后不是立刻返回給客戶端,而是等待至少一個從庫接收到并寫到relay log中才返回給客戶端。相對于異步復制,半同步復制提高了數據的安全性,同時它也造成了一定程度的延遲,這個延遲最少是一個TCP/IP往返的時間。所以,半同步復制最好在低延時的網絡中使用。
半同步復制原理:
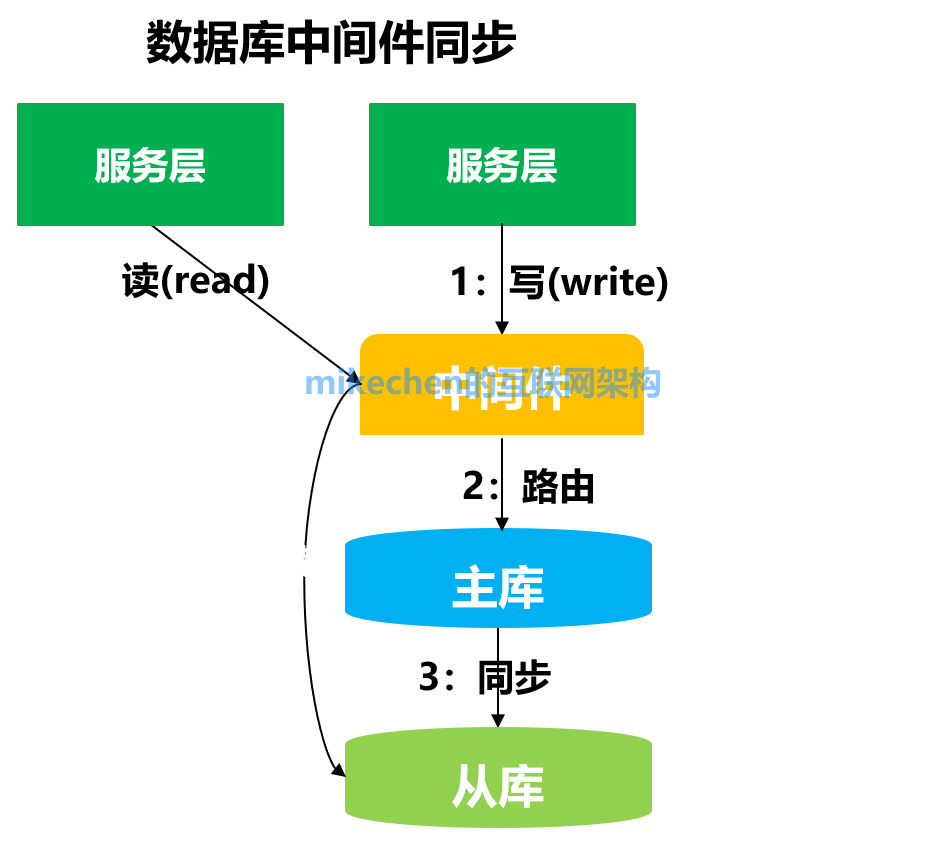
該方案優點: 利用數據庫原生功能,比較簡單 該方案缺點: 主庫的寫請求時延會增長,吞吐量會降低 2.數據庫中間件
流程: 1)所有的讀寫都走數據庫中間件,通常情況下,寫請求路由到主庫,讀請求路由到從庫 2)記錄所有路由到寫庫的key,在主從同步時間窗口內(假設是500ms),如果有讀請求訪問中間件,此時有可能從庫還是舊數據,就把這個key上的讀請求路由到主庫。 3)在主從同步時間過完后,對應key的讀請求繼續路由到從庫。 相關的中間件有: 1)canal:是阿里巴巴旗下的一款開源項目,純Java開發,基于數據庫增量日志解析,提供增量數據訂閱&消費,目前主要支持了MySQL。 2)otter:也是阿里開源的一個分布式數據庫同步系統,尤其是在跨機房數據庫同步方面,有很強大的功能。它是基于數據庫增量日志解析,實時將數據同步到本機房或跨機房的mysql/oracle數據庫。 兩者的區別在于: otter目前嵌入式依賴canal,部署為同一個jvm,目前設計為不產生Relay Log。 otter目前允許自定義同步邏輯,解決各類需求。 該方案優點 能保證絕對一致 該方案缺點: 數據庫中間件的成本較高 3.緩存記錄寫key法
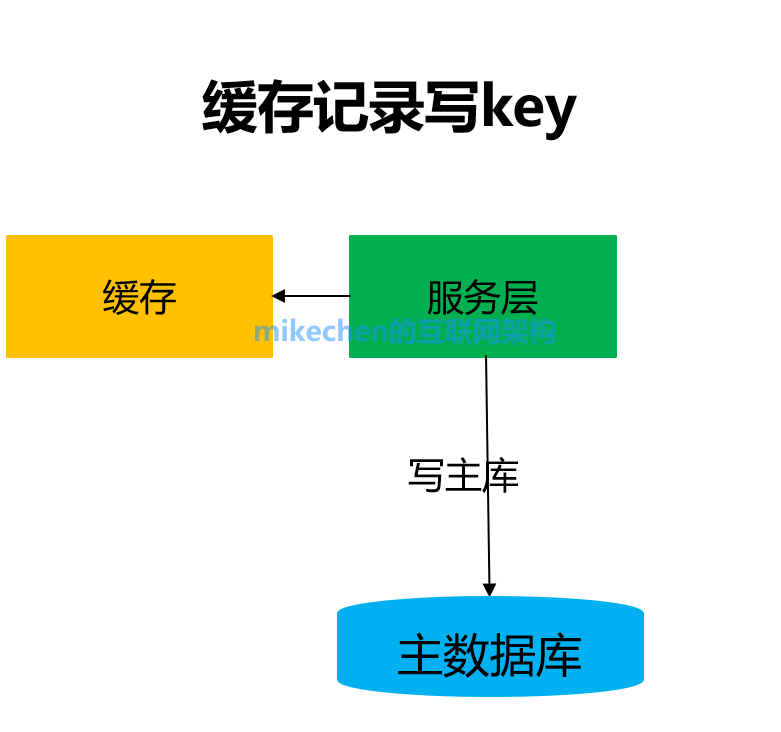
寫流程: 1)如果key要發生寫操作,記錄在cache里,并設置“經驗主從同步時間”的cache超時時間,例如500ms 2)然后修改主數據庫 讀流程: 1)先到緩存里查看,對應key有沒有相關數據 2)有相關數據,說明緩存命中,這個key剛發生過寫操作,此時需要將請求路由到主庫讀最新的數據。 3)如果緩存沒有命中,說明這個key上近期沒有發生過寫操作,此時將請求路由到從庫,繼續讀寫分離。 該方案優點: 相對數據庫中間件,成本較低 該方案缺點: 為了保證“一致性”,引入了一個cache組件,并且讀寫數據庫時都多了緩存操作。 以上就是數據庫主從同步一致性方案詳解,如果有興趣了解更加深入的分布式大數據分布式文件系統和分布式數據庫的一致性,可以到我的博客mikechen查看:分布式數據庫數據一致性的原理、與技術實現方案(文章)~ 閱讀原文:原文鏈接 該文章在 2025/7/1 23:53:14 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886