Kafka工作原理圖解,看這篇就夠了!
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
之前我就講過消息中間件那真的是太重要了,那就是億級互聯網架構的基石,實在是太重要了,當然這肯定也是大廠必備技能了。 很多同學留言給我:學哪個消息中間件?那肯定是學主流中間件,比如:Kafka、RocketMQ,本篇就先來談談Kafka的底層架構以及實現原理。 希望本篇,對你掌握好消息中間件有所幫助@mikechen Kafka核心架構 它的架構包括以下組件:
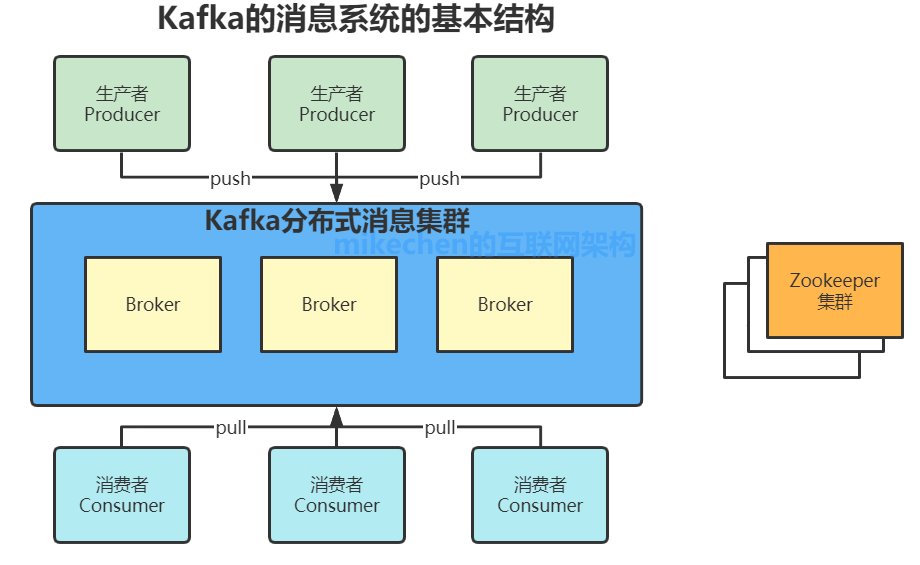
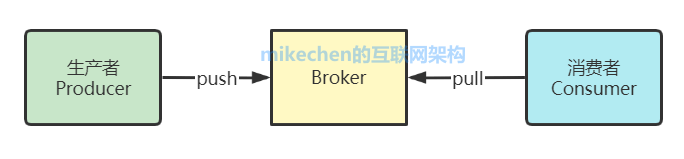
1、話題(Topic):是特定類型的消息流。消息是字節的有效負載(Payload),話題是消息的分類名; 2、生產者(Producer):是能夠發布消息到話題的任何對象; 3、服務代理(Broker):已發布的消息保存在一組服務器中,它們被稱為代理(Broker)或Kafka集群; 4、消費者(Consumer):可以訂閱一個或多個話題,并從Broker拉數據,從而消費這些已發布的消息; 上圖中可以看出,生產者將數據發送到Broker代理,Broker代理有多個話題topic,消費者從Broker獲取數據。 Kafka原理機制我們將消息的發布(publish)稱作 producer,將消息的訂閱(subscribe)表述為 consumer,將中間的存儲陣列稱作 broker(代理),這樣就可以大致描繪出這樣一個場面:
生產者將數據生產出來,交給 broker 進行存儲,消費者需要消費數據了,就從broker中去拿出數據來,然后完成一系列對數據的處理操作。
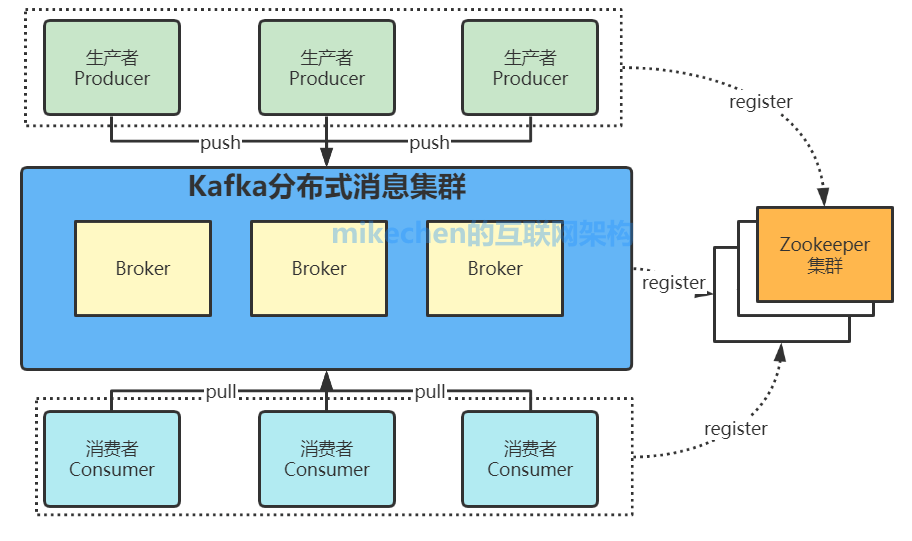
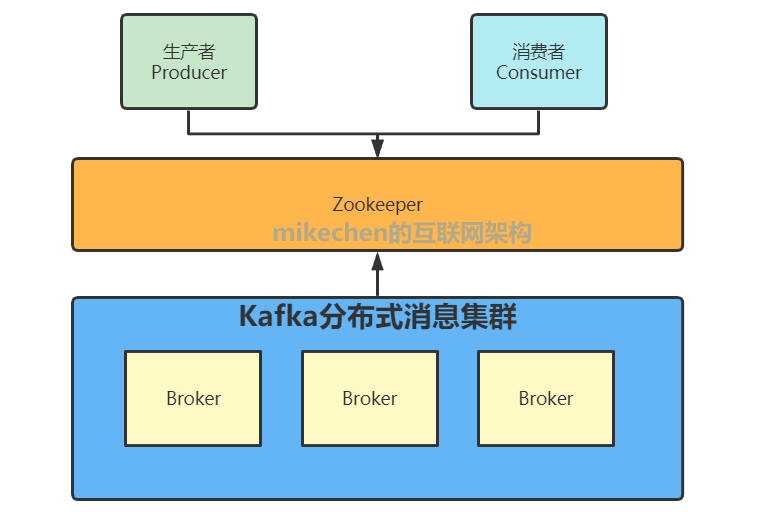
多個 broker 協同合作,producer 和 consumer 部署在各個業務邏輯中被頻繁的調用,三者通過 zookeeper管理協調請求和轉發,這樣一個高性能的分布式消息發布訂閱系統就完成了。 圖上有個細節需要注意,producer 到 broker 的過程是 push,也就是有數據就推送到 broker,而 consumer 到 broker 的過程是 pull,是通過 consumer 主動去拉數據的。 Zookeeper在kafka的作用
(1)無論是kafka集群,還是producer和consumer都依賴于zookeeper來保證系統可用性集群保存一些meta信息。 (2)Kafka使用zookeeper作為其分布式協調框架,很好的將消息生產、消息存儲、消息消費的過程結合在一起。 (3)同時借助zookeeper,kafka能夠生產者、消費者和broker在內的所以組件在無狀態的情況下,建立起生產者和消費者的訂閱關系,并實現生產者與消費者的負載均衡。 Kafka的特性1.高吞吐量、低延遲 kafka每秒可以處理幾十萬條消息,它的延遲最低只有幾毫秒,每個topic可以分多個partition, consumer group 對partition進行consume操作。 2.可擴展性 kafka集群支持熱擴展 3.持久性、可靠性 消息被持久化到本地磁盤,并且支持數據備份防止數據丟失 4.容錯性 允許集群中節點失敗(若副本數量為n,則允許n-1個節點失敗) 5.高并發 支持數千個客戶端同時讀寫 Kafka的應用場景
1.日志收集 一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一接口服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等。 2.消息系統 解耦和生產者和消費者、緩存消息等。 3.用戶活動跟蹤 Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動信息被各個服務器發布到kafka的topic中,然后訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、數據倉庫中做離線分析和挖掘。 4.運營指標 Kafka也經常用來記錄運營監控數據。包括收集各種分布式應用的數據,生產各種操作的集中反饋,比如報警和報告。 5.流式處理 比如spark streaming和storm 閱讀原文:原文鏈接 該文章在 2025/7/2 0:07:38 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886