一文看懂:MCP(大模型上下文協議)
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
 :一文看懂:MCP(大模型上下文協議) :一文看懂:MCP(大模型上下文協議) ? MCP逐漸被接受,是因為MCP是開放標準。在AI項目開發中可以發現,集成AI模型復雜,現有框架如LangChain Tools、LlamaIndex和Vercel AI SDK存在問題。LangChain和LlamaIndex代碼抽象高,商業化過重;Vercel AI SDK與Nextjs綁定過深。MCP的優勢:一是開放標準利于服務商開發API,二是避免重復造輪子,可利用現有MCP服務增強Agent。 本文部分轉自 https://guangzhengli.com/blog/zh/model-context-protocol/ 一、什么是MCP(Model Context Protocol)定義MCP(Model Context Protocol,模型上下文協議) ,2024年11月底,由 Anthropic 推出的一種開放標準,旨在統一大模型與外部數據源和工具之間的通信協議。MCP 的主要目的在于解決當前 AI 模型因數據孤島限制而無法充分發揮潛力的難題,MCP 使得 AI 應用能夠安全地訪問和操作本地及遠程數據,為 AI 應用提供了連接萬物的接口。 Function Calling是AI模型調用函數的機制,MCP是一個標準協議,使大模型與API無縫交互,而AI Agent是一個自主運行的智能系統,利用Function Calling和MCP來分析和執行任務,實現特定目標。 MCP 的價值舉個栗子,在過去,為了讓大模型等 AI 應用使用數據,要么復制粘貼,要么上傳知識庫,非常局限。 即使是最強大模型也會受到數據隔離的限制,形成信息孤島,要做出更強的大模型,每個新數據源都需要自己重新定制實現,使真正互聯的系統難以擴展,存在很多的局限性。 現在,MCP 可以直接在 AI 與數據(包括本地數據和互聯網數據)之間架起一座橋梁,通過 MCP 服務器和 MCP 客戶端,大家只要都遵循這套協議,就能實現“萬物互聯”。 有了MCP,可以和數據和文件系統、開發工具、Web 和瀏覽器自動化、生產力和通信、各種社區生態能力全部集成,實現強大的協作工作能力,它的價值遠不可估量。 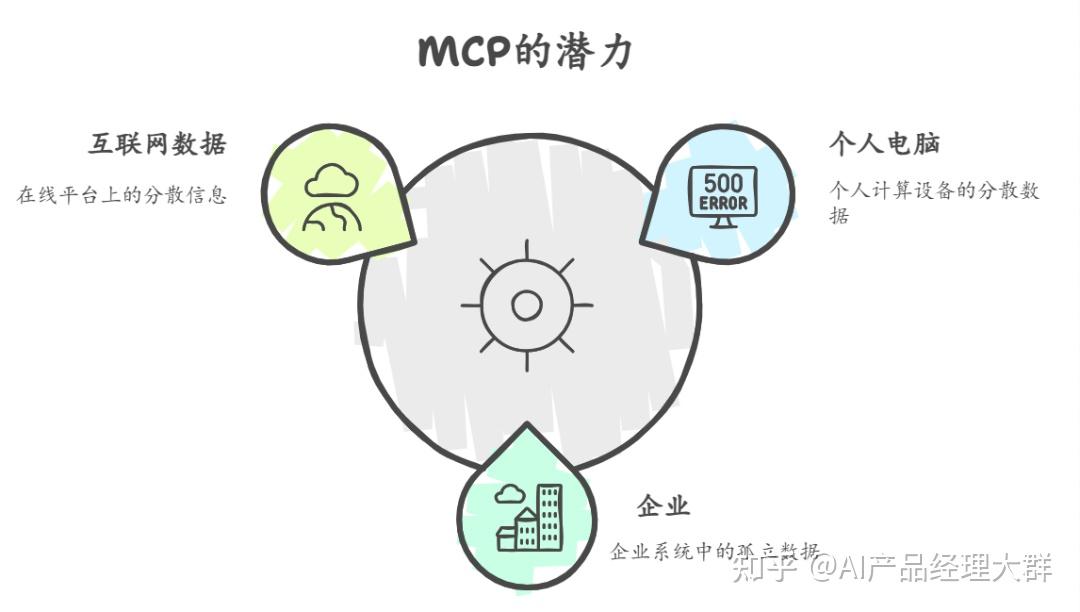 MCP 與 Function Calling 的區別
這兩種技術都旨在增強 AI 模型與外部數據的交互能力,但 MCP 不止可以增強 AI 模型,還可以是其他的應用系統。 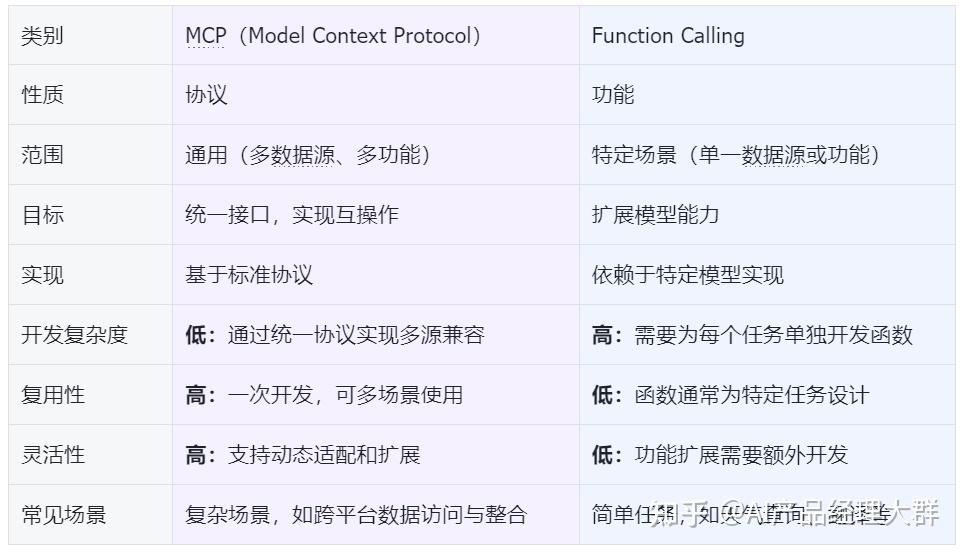 數據安全性這樣一個理想的“萬物互聯”生態系統看著很讓人著迷。 但是大家是不是擔心通過 MCP Server 暴露出來的數據會泄露或被非法訪問,這個頭疼的問題 MCP 也考慮到了。 MCP 通過標準化的數據訪問接口,大大減少了直接接觸敏感數據的環節,降低了數據泄露的風險。 還有,MCP 內置了安全機制,確保只有經過驗證的請求才能訪問特定資源,相當于在數據安全又加上了一道防線。同時,MCP協議還支持多種加密算法,以確保數據在傳輸過程中的安全性。 例如,MCP 服務器自己控制資源,不需要將 API 密鑰等敏感信息提供給 LLM 提供商。這樣一來,即使 LLM 提供商受到攻擊,攻擊者也無法獲取到這些敏感信息。 不過,MCP 這套協議/標準,需要大家一起來共建,這個生態才會繁榮,現在,只是測試階段,一切才剛剛開始,當然,還會涌現出更多的問題。 工作原理MCP 協議采用了一種獨特的架構設計,它將 LLM 與資源之間的通信劃分為三個主要部分:客戶端、服務器和資源。 客戶端負責發送請求給 MCP 服務器,服務器則將這些請求轉發給相應的資源。這種分層的設計使得 MCP 協議能夠更好地控制訪問權限,確保只有經過授權的用戶才能訪問特定的資源。 以下是 MCP 的基本工作流程:
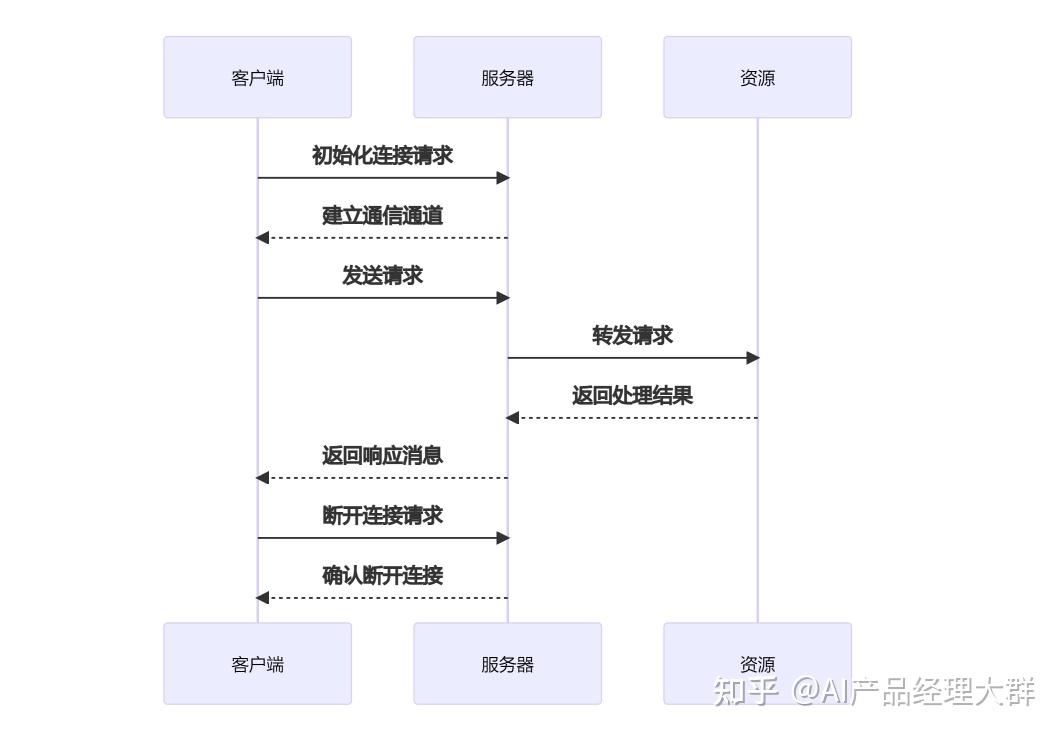 MCP 核心架構MCP 遵循客戶端-服務器架構(client-server),其中包含以下幾個核心概念:
 MCP Client MCP client 充當 LLM 和 MCP server 之間的橋梁,MCP client 的工作流程如下:
Claude Desktop 和Cursor都支持了MCP Server接入能力,它們就是作為 MCP client來連接某個MCP Server感知和實現調用。 MCP Server MCP server 是 MCP 架構中的關鍵組件,它可以提供 3 種主要類型的功能:
這些功能使 MCP server 能夠為 AI 應用提供豐富的上下文信息和操作能力,從而增強 LLM 的實用性和靈活性。 你可以在 MCP Servers Repository 和 Awesome MCP Servers 這兩個 repo 中找到許多由社區實現的 MCP server。使用 TypeScript 編寫的 MCP server 可以通過 npx 命令來運行,使用 Python 編寫的 MCP server 可以通過 uvx 命令來運行。 通信機制MCP 協議支持兩種主要的通信機制:基于標準輸入輸出的本地通信和基于SSE(Server-Sent Events)的遠程通信。 這兩種機制都使用 JSON-RPC 2.0 格式進行消息傳輸,確保了通信的標準化和可擴展性。
二、MCP的功能與應用:如何使用 MCP如果你還沒有嘗試過如何使用 MCP 的話,我們可以考慮用 Cursor(本人只嘗試過 Cursor),Claude Desktop 或者 Cline 來體驗一下。 當然,我們并不需要自己開發 MCP Servers,MCP 的好處就是通用、標準,所以開發者并不需要重復造輪子(但是學習可以重復造輪子)。 首先推薦的是官方組織的一些 Server:官方的 MCP Server 列表。 目前社區的 MCP Server 還是比較混亂,有很多缺少教程和文檔,很多的代碼功能也有問題,我們可以自行嘗試一下 Cursor Directory 的一些例子,具體的配置和實戰筆者就不細講了,大家可以參考官方文檔。 MCP的功能MCP通過引入多樣化的MCP Server能力,顯著增強了AI工具的功能,例如我們常用的Cursor和Claude。以下是一些官方參考服務器,展示了MCP的核心功能和SDK的應用: 數據與文件系統: 文件系統:提供安全文件操作,帶可配置的訪問控制。 PostgreSQL:提供只讀數據庫訪問,具備架構檢查功能。 SQLite:支持數據庫交互和商業智能功能。 Google Drive:實現Google Drive的文件訪問和搜索功能。 開發工具: Git:工具用于讀取、搜索和操作Git倉庫。 GitHub:集成倉庫管理、文件操作和GitHub API。 GitLab:支持項目管理的GitLab API集成。 Sentry:從http://Sentry.io獲取并分析問題。 網絡與瀏覽器自動化: Brave Search:利用Brave的搜索API進行網絡和本地搜索。 Fetch:為LLM優化的網絡內容獲取和轉換。 Puppeteer:提供瀏覽器自動化和網頁抓取功能。 生產力和通信: Slack:支持頻道管理和消息功能。 Google Maps:提供位置服務、路線和地點詳情。 Memory:基于知識圖譜的持久記憶系統。 AI與專業工具: EverArt:使用多種模型進行AI圖像生成。 Sequential Thinking:通過思維序列進行動態問題解決。 AWS KB Retrieval:使用Bedrock Agent Runtime從AWS知識庫檢索。 官方集成工具: 這些MCP服務器由公司維護,用于其平臺: Axiom:使用自然語言查詢和分析日志、跟蹤和事件數據。 Browserbase:云端自動化瀏覽器交互。 Cloudflare:在Cloudflare開發者平臺上部署和管理資源。 E2B:在安全的云沙箱中執行代碼。 Neon:與Neon無服務器Postgres平臺交互。 Obsidian Markdown Notes:讀取和搜索Obsidian知識庫中的Markdown筆記。 Qdrant:使用Qdrant向量搜索引擎實現語義記憶。 Raygun:訪問崩潰報告和監控數據。 Search1API:統一的API用于搜索、爬蟲和網站地圖。 Tinybird:與Tinybird無服務器ClickHouse平臺交互。 集成工具: Docker:管理容器、鏡像、卷和網絡。 Kubernetes:管理pod、部署和服務。 Linear:項目管理和問題跟蹤。 Snowflake:與Snowflake數據庫交互。 Spotify:控制Spotify播放和管理播放列表。 Todoist:任務管理集成。 三、怎么使用和開發MCP Server使用目前支持的部分工具列表(更多見這里):
Claude Desktop 使用示例以 Claude Desktop 為例,配置 MCP 客戶端的步驟如下:
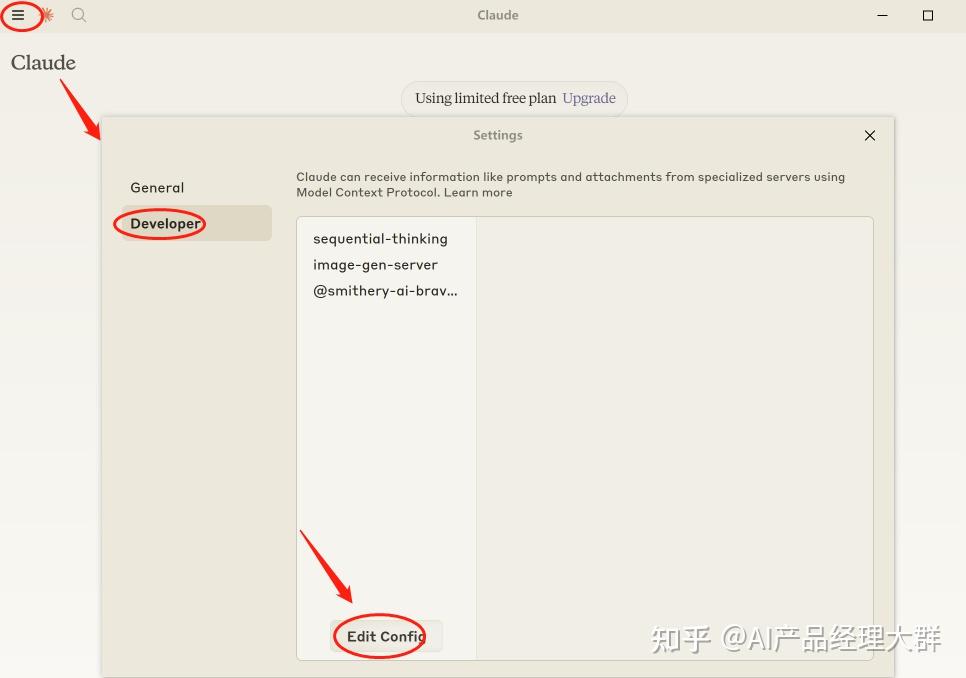
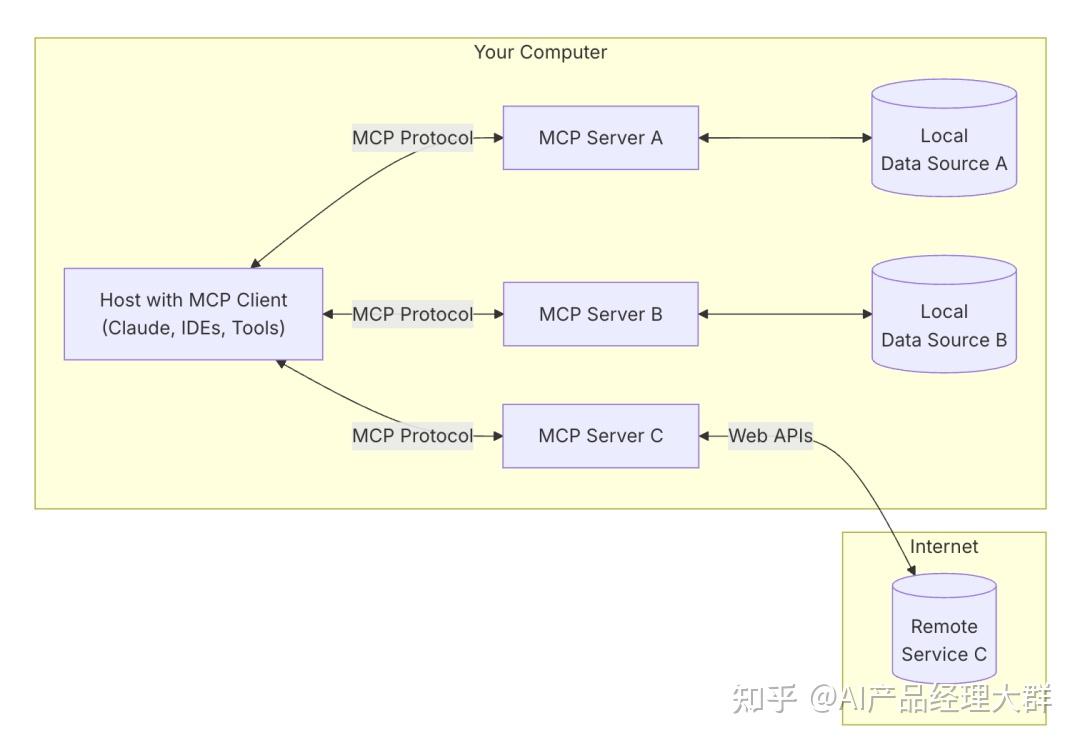
這里的@modelcontextprotocol/server-filesystem、mcp-server-git是對應的一些MCP Server,可以是開源找來的,也可以是你自己開發的。 配置完后,在主界面對話題右下角就有個錘子出現了,有幾個錘子就是配置幾個,然后對話中如果涉及使用該工具的,claude就會自動調用  Cursor中 使用示例Cursor工具中集成mcp server功能對開發增加效率非常明顯,配置入口在:文件—>首選項—>Cursor Settings—>Features—>MCP Server—>Add new MCP Server  配置完后,你需要畫圖的地方給它提要求就行了,它會自動感知,按上下文生成prompt并調用工具生成圖片: 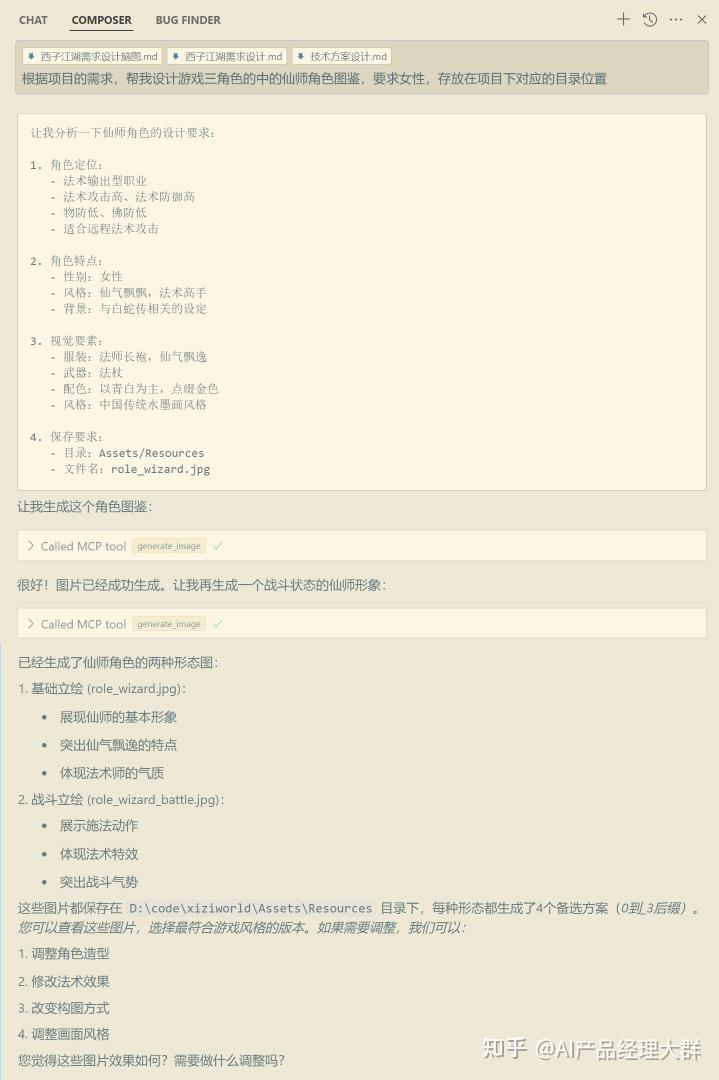 生成的圖片質量還不錯,符合開發需要的圖片  MCP 如何工作那我們來介紹一下 MCP 的工作原理。首先我們看一下官方的 MCP 架構圖。 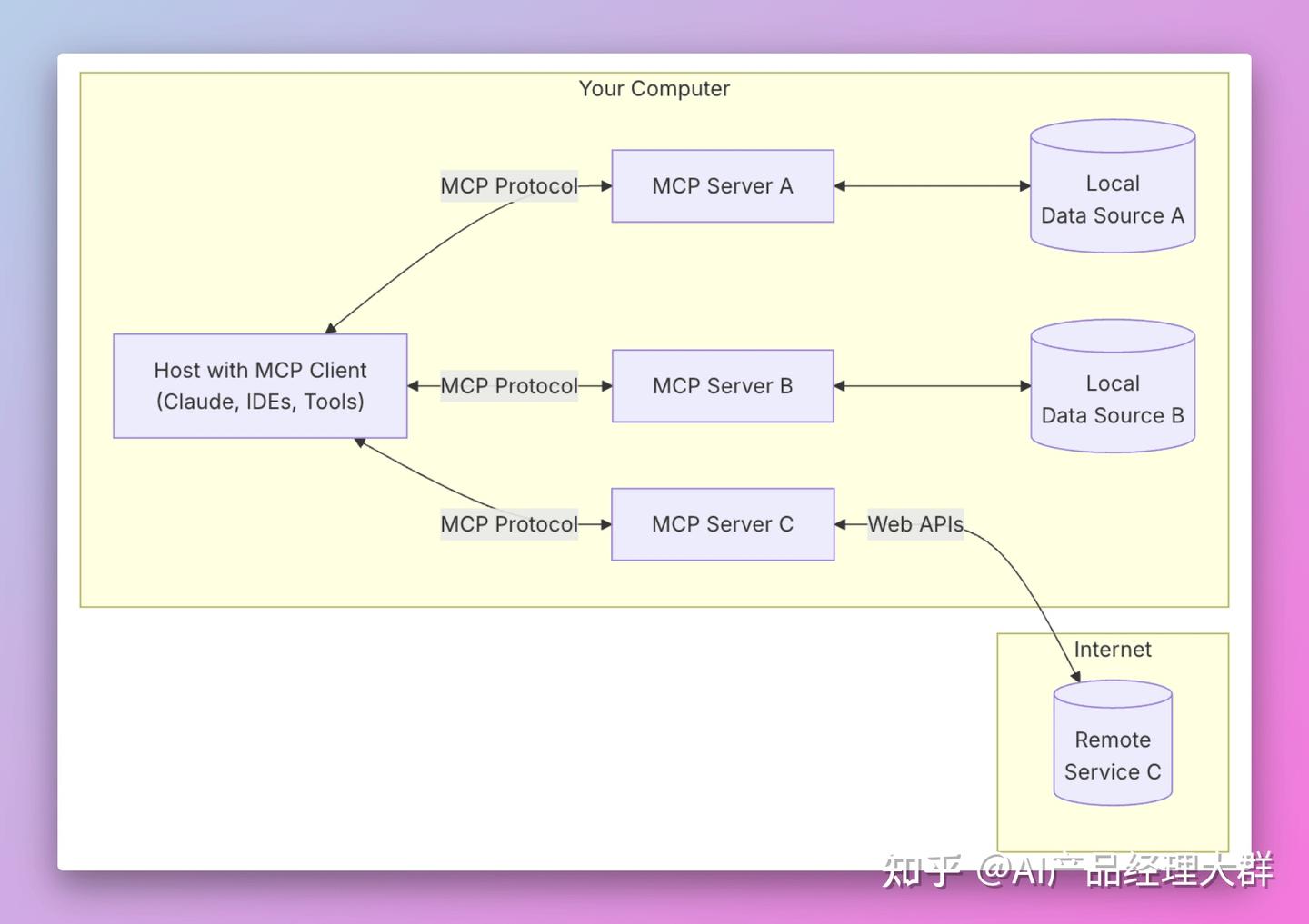 總共分為了下面五個部分:
整個 MCP 協議核心的在于 Server,因為 Host 和 Client 相信熟悉計算機網絡的都不會陌生,非常好理解,但是 Server 如何理解呢? 看看 Cursor 的 AI Agent 發展過程,我們會發現整個 AI 自動化的過程發展會是從 Chat 到 Composer 再進化到完整的 AI Agent。 AI Chat 只是提供建議,如何將 AI 的 response 轉化為行為和最終的結果,全部依靠人類,例如手動復制粘貼,或者進行某些修改。 AI Composer 是可以自動修改代碼,但是需要人類參與和確認,并且無法做到除了修改代碼之外的其它操作。 AI Agent 是一個完全的自動化程序,未來完全可以做到自動讀取 Figma 的圖片,自動生產代碼,自動讀取日志,自動調試代碼,自動 push 代碼到 GitHub。 而 MCP Server 就是為了實現 AI Agent 的自動化而存在的,它是一個中間層,告訴 AI Agent 目前存在哪些服務,哪些 API,哪些數據源,AI Agent 可以根據 Server 提供的信息來決定是否調用某個服務,然后通過 Function Calling 來執行函數。 MCP Server 的工作原理我們先來看一個簡單的例子,假設我們想讓 AI Agent 完成自動搜索 GitHub Repository,接著搜索 Issue,然后再判斷是否是一個已知的 bug,最后決定是否需要提交一個新的 Issue 的功能。 那么我們就需要創建一個 Github MCP Server,這個 Server 需要提供查找 Repository、搜索 Issues 和創建 Issue 三種能力。 我們直接來看看代碼: 上面的代碼中,我們通過 我們再來看看具體的實現代碼: 可以很清晰的看到,我們最終實現是通過了 在調用 Github 官方的 API 之前,MCP 的主要工作是描述 Server 提供了哪些能力(給 LLM 提供),需要哪些參數(參數具體的功能是什么),最后返回的結果是什么。 所以 MCP Server 并不是一個新穎的、高深的東西,它只是一個具有共識的協議。 如果我們想要實現一個更強大的 AI Agent,例如我們想讓 AI Agent 自動的根據本地錯誤日志,自動搜索相關的 GitHub Repository,然后搜索 Issue,最后將結果發送到 Slack。 那么我們可能需要創建三個不同的 MCP Server,一個是 Local Log Server,用來查詢本地日志;一個是 GitHub Server,用來搜索 Issue;還有一個是 Slack Server,用來發送消息。 AI Agent 在用戶輸入 參考資源下面是個人推薦的一些 MCP 的資源,大家可以參考一下。 MCP 官方資源社區的 MCP Server 的列表該文章在 2025/6/27 17:50:40 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


